
人工智慧無所不在 看Google如何用機器學習找到行星及識別基因變體
人工智慧正悄悄在我們身邊蔓延,知道如何運用便可為生活帶來改善。目前Google正以機器學習技術協助天文領域及生命科學的研究,而這些技術都是開源的,原理也不難,或許也有機會對你正在進行的工作帶來幫助。
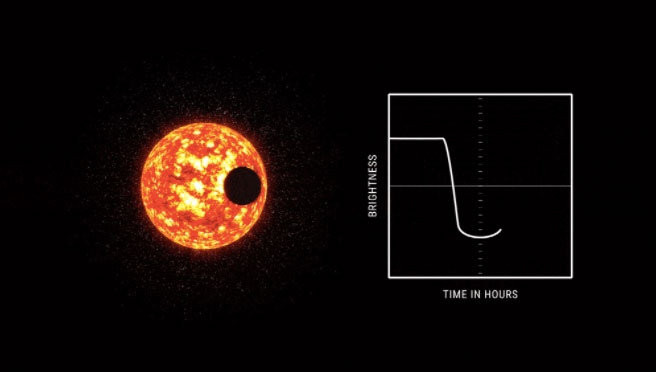
美國國家航空暨太空總署(National Aeronautics and Space Administration,NASA)自2009年5月開始進行克卜勒任務(Kepler mission),以克卜勒太空望遠鏡探索宇宙中與地球類似的行星。怎麼探索呢?利用行星繞行恆星時,恆星發出的亮度會改變來得知。
他們在四年期間蒐集超過20萬顆恆星的亮度,然後平均每30分鐘記錄一次每顆恆星的亮度,每顆恆星至今已記錄大約7萬次亮度。當發現恆星亮度有變化時,代表這顆恆星可能有行星在環繞。目前天文學家用人工檢查超過3萬個亮度訊號,已經發現約有2,500個訊號是行星。
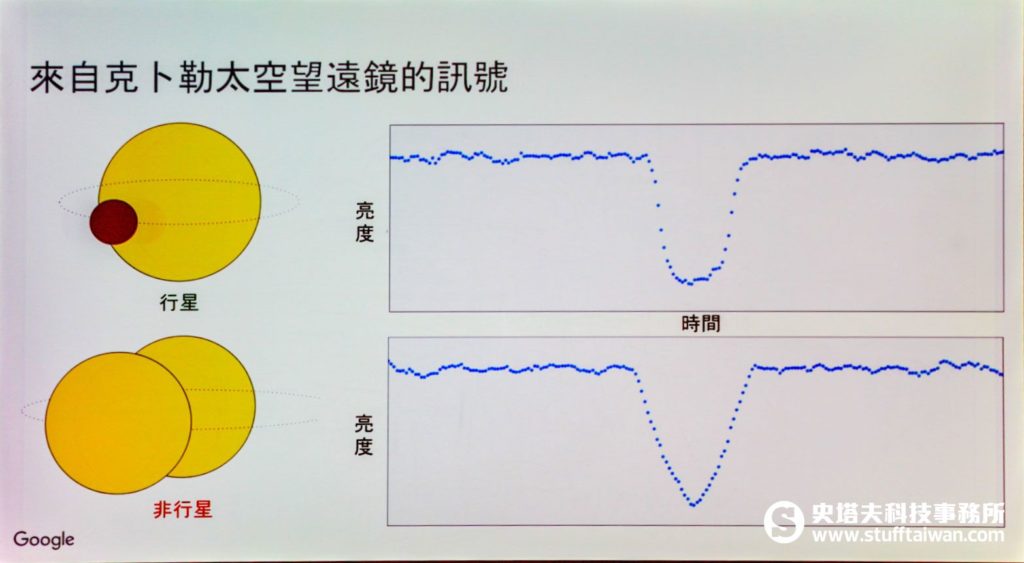
不過許多因素也會造成恆星亮度的變化,比如恆星上的斑點、兩顆恆星彼此繞行、太空船轉動方向等。還有大量訊號因為有雜訊或太弱而無法用人工檢查,像這樣的情況,就非常適合用機器學習來幫助。
卷積神經網路(convolutional neural network)是機器學習的一種運算模型,通常用於圖像分類,Google相簿就有用到這個技術。在NASA與Google的合作計畫中,他們採用15,000組訊號圖像來訓練模型,教機器學習哪種亮度曲線圖代表是行星、哪種不是。
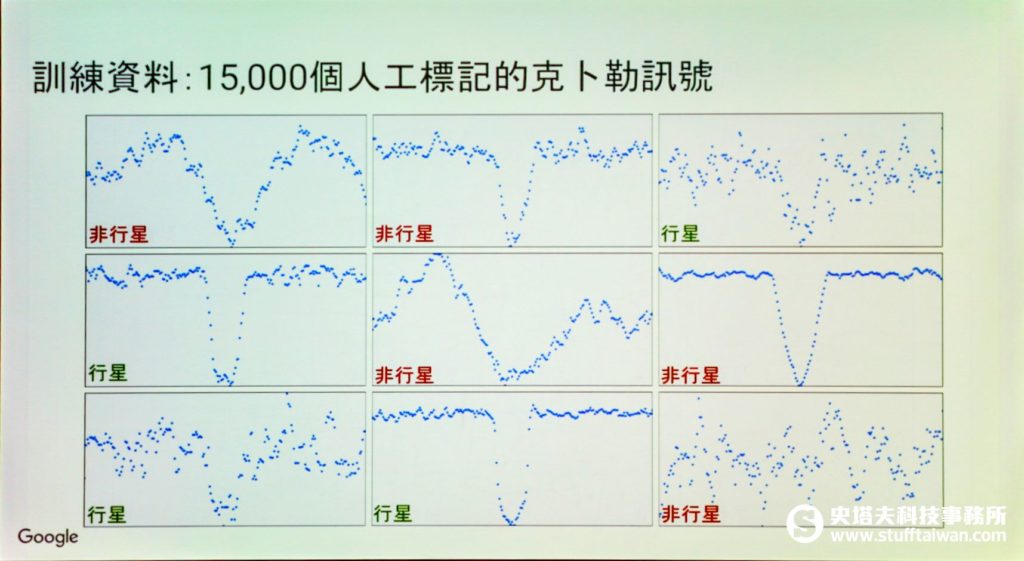
透過這個方式,他們再度搜尋克卜勒資料庫中的670顆恆星,又找到了兩顆新行星,分別是克卜勒-90i和克卜勒-80g。克卜勒90星系更是目前已知第一個與我們所處的太陽系同樣擁有8顆行星數的星系,克卜勒-90i是克卜勒90星系中最小的一顆。
Google Brain研究團隊資深軟體工程師Chris Shallue表示,比較微弱的訊號要找到行星的機會本就比較低,不值得用人工去找。此類訊號先用機器學習模型大量篩選,再由天文學家們判斷就會比較有效率。
類似的圖像分類技術也可用在基因組測序與變體識別(Variant Calling)上。
藉由比對個體基因和人類參考組基因的差異,識別變體,可以幫助解決許多病例。例如當新生兒發現無法解釋的疾病時,可使用基因組測序比對是否有變體,是否有可解釋的病因,如果是遺傳性疾病的話便有機會處理。或是用來判斷癌症的標靶治療是否有效。
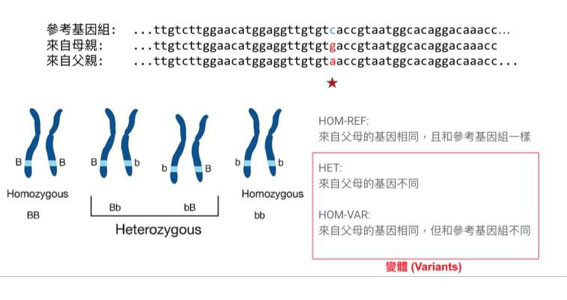
但基因組序列資料量很大,DNA讀序相當片段,有諸多不可控制的錯誤。現有的變體識別工具仰賴大量人工設計、手調參數,需花費專家多年時間,也很難快速推廣至新的測序技術。
於是Verily Life Sciences與Google Brain團隊花了兩年多開發出DeepVariant,這是一個提高基因組測序準確性的工具。先將基因測序儀所讀到的數據編碼成圖像格式,透過常見的圖像分類演算法,訓練出準確的變體識別模型。如此一來,就可以從數據中直接學習哪種參數最有用,而不需要人工手調,從而加速新測序技術的實施。
Google Brain研究團隊資深軟體工程師張碧娟(Pi-Chuan Chang)表示,DeepVariant也可用在人類以外的生物上。例如將食品拿去測序,可知道是否含有大腸桿菌,哪種大腸桿菌,會不會致病。目前他們應用在老鼠、米上的變體識別已有很高的準確率,未來如果有臨床機會他們也有意願參與,歡迎有興趣合作的單位與他們聯絡。
Google台灣董事總經理簡立峰表示,AI很重要的一部分是跨領域研究,現在的AI工具很方便,試試看這些工具或許會對某個領域有更大的幫助,可能是更快速、更好的結果,值得台灣發展重視。
他提到Google的工具、實驗數據都是開放原始碼,讓大家可以繼續接手做下去,這是電腦科學界的習慣,開放取得的要回饋給社群繼續發展。開放原始碼讓一般工程師也能對科學有所貢獻,這樣的風氣和運用習慣若其他領域可以了解,不是只有資訊界,台灣發展速度就會更快。
例如基因檢測領域,台灣有新創投入也已經有成果,若能繼續結合機器學習、開放原始碼會有很大幫助。像中央研究院有很多基因資料庫正在建置中,透過開放工具讓技術提高,改善病蟲害、人體疾病、農作物等,都是值得發展的方向。
史塔夫短評:要趕快站到人工智慧的舞台上啊。